LinkedList 是 Collection 接口下对 List 的双向链表实现。
概述:
- 同时实现了
List接口和Deque接口 - 每次插入时可选择链表头或链表尾插入
- 读取时需从链式结构逐个遍历,删除则为断链-重链过程
- 非线程安全
与 ArrayList 相比:
- 优势:不需要预估容量及动态扩容,每次新增只需要新增一个链上的节点。
- 代价:遍历时需从链上逐个遍历,不支持随机访问。
构造函数
1 | public LinkedList() { // 无参空构造函数 |
链表节点的数据结构
Java 中所有链表的实现均为双向链接:每个节点还存放着指向前驱节点的引用。
1 | private static class Node<E> { |
链表与泛型集合的区别:
链表为有序集合,每个对象的位置十分重要
- 将元素添加至链表中间时,需要依赖链表的位置;而迭代器负责描述集合中位置
- 即:LinkedList.add() 由迭代器负责(只有对自然有序的集合使用迭代器添加元素才有实际意义)
集合类库提供子接口 ListIterator,包含 add()
1 | package java.util; |
基本操作
添加元素
1 | /** |
删除元素
1 | /** |
总结如下:
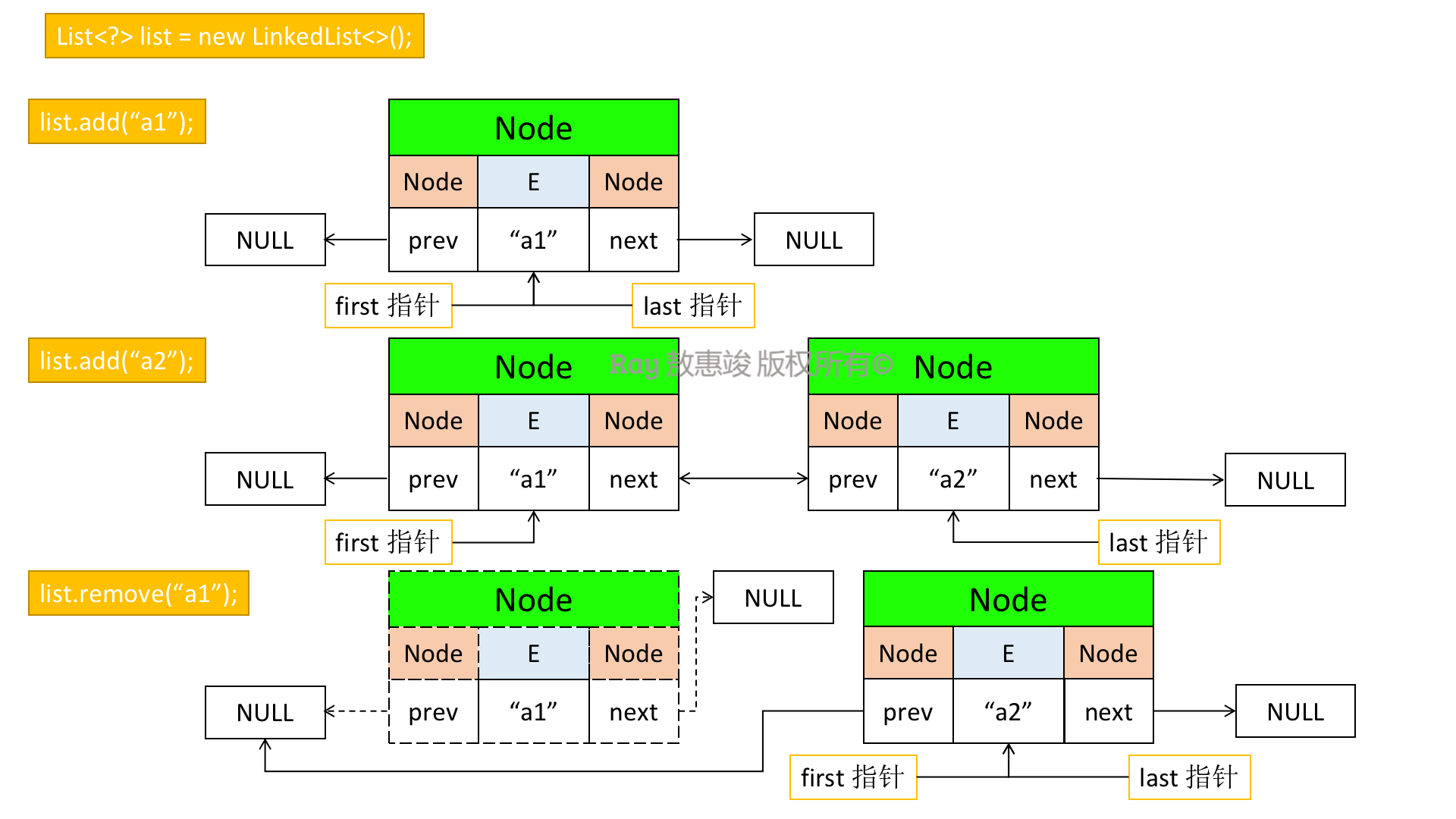
获取元素
1 | /** |
注:
删除元素和获取元素中重要的算法:node(int index)
1 | /** |
由此可知 LinkedList 继承了链表获取元素方法的缺点:不支持快速随机访问,查询需要从头查起。
迭代元素
1 | // 调用: |
多次调用
listIterator.add(element):元素被依次添加到迭代器当前位置之前1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/*
注:初始化迭代器时,如果 index 是链表最后一位(index == size):next = null;
否则 next = (index 下标对应的节点)
*/
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null) {
linkLast(e);
} else {
linkBefore(e, next); // 将 e 添加到 index 对应节点之前
}
nextIndex++;
expectedModCount++;
}n 个元素的链表有 n+1 个位置可以添加新元素
注:
- 调用 next() 之后,再调用 remove() 会删除迭代器左侧元素,调用 previous() 会删除其右侧元素(改变迭代器中 next 的状态)
1 | public E next() { |
set():用新元素取代 next() 或 previous() 返回的上一个元素
1 | public void set(E e) { |
但链表只负责跟踪对链表的结构性修改,如添加元素、删除元素;set() 不被视为结构性修改。
故可以将多个迭代器附加给一个链表,所有迭代器都调用 set() 对现有结点内容进行修改。
不过,依据原理,列表迭代器可返回迭代器所在位置前后两元素的索引
nextIndex()返回下一次调用 next() 时返回的元素索引previousIndex()返回下一次调用 previous() 时返回的元素索引(比 nextIndex 小 1)
多线程访问链表时,需处理好非线程安全的操作;否则会抛出 ConcurrentModificationException 异常。
ArrayList v.s. LinkedList
ArrayList 实现了基于动态数组的数据结构,由 Array 支持,提供对元素的随机访问,复杂度为 O(1)。
LinkedList 使用双向链表实现存储(实现 List 和 Deque 接口),虽然有使用索引获取元素的方法,但按照序号索引数据的实现,需要进行前向或后向遍历,复杂度为 O(n);
LinkedList 插入数据时只需要记录本项的前后项即可,所以插入速度较快。
因为采用了双向链表,所以 LinkedList 会消耗更多的内存。
操作对比
- 查找操作 indexOf(),lastIndexOf(),contains() 的性能,两者差不多;
- 对于随机访问 get 和 set,ArrayList 优于 LinkedList,因为 LinkedList 操作时要移动指针;
- 而对于新增和删除操作 add 和 remove,LinkedList 比较占优势,因为 ArrayList 操作时要移动数据
- 若只对单条数据插入或删除,ArrayList 的速度反而优于 LinkedList;
- 若随机插入批量数据,LinkedList 的速度则大大优于 ArrayList:因为ArrayList 每插入一条数据,要移动插入点及以后的所有数据。
实际应用中怎么选?
- 如链表仅含几个元素,完全没必要为 set() 和 get() 开销而烦恼,完全可使用 ArrayList
- 优先使用链表的情况,应该是尽可能减少在列表中间插入或删除元素开销的场景中
- 注:动态数组中可能使用 Vector 类,但该类所有方法均为同步,开销大