线程安全集合类是 Java 除了并发工具类和多线程执行器之外,另外一种成熟的并发编程解决方案。
在还没有推出线程安全集合的早期,开发任务使用 Collections 工具类中的同步包装器 来实现线程安全的集合操作:
1 2 3 4 5 6 static <E> Collection<E> synchronizedCollection (Collection<E> c) static <E> List synchronizedList (List<E> l) static <E> Set synchronizedSet (Set<E> s) static <E> SortedSet synchronizedSortedSet (SortedSet<E> s) static <K, V> Map<K, V> synchronizedMap (Map<K, V> m) static <K, V> SortedMap<K, V> synchronizedSortedMap (SortedMap<K, V> s)
Java 在后来的 JDK 中推出了两个线程安全的集合类:
至今,在 JCF 中的同步接口包括:1 2 3 4 5 BlockingDeque BlockingQueue ConcurrentMap ConcurrentNavigableMap TransferQueue
以上都是能够避免 ConcurrentModificationException 的类和方法。
我们先从阻塞队列开始说起。
阻塞队列 阻塞队列使用一个锁(入队和出队使用同一个锁)或两个锁(入队和出队分别使用不同的锁)实现数据的同步操作。
阻塞插入:当队列满的时候,队列会阻塞插入元素的线程,直到队列有空缺为止;
生产者 / 消费者模型中用得比较多。
方法 / 特殊情况处理方式
抛出异常
返回特殊值
超时退出
一直阻塞
插入方法
add(e)
o ffer(e)o ffer(e, time, unit)put (e)
移除方法
remove()
po ll()
po ll(time, unit)
t ake()
检查方法
element()
peek()
-
-
方法
正常动作
特殊情况动作
add
添加元素(添加 null 值非法)
队列满时抛出 IllegalStateException("Queue full")
offer
添加元素并返回 true
队列满时返回 false
put
添加元素
队列满时阻塞
remove
移除并返回队列头元素
队列空时抛出 NoSuchElementException
poll
移除并返回队列头元素
队列空时返回 null
take
移除并返回队列头元素
队列空时阻塞
element
返回队列头元素
队列空时抛出 NoSuchElementException
peek
返回队列头元素
队列空时返回 null
注意:使用无界队列时,put() 永远不会阻塞,offer() 永远返回 true。
阻塞队列使用通知模式 实现:
生产者往满队列添加元素时,生产者会被阻塞;
消费者将满队列中的一个元素消费掉之后,通知生产者当前队列可用。
在 JCF 中,阻塞队列对应着 BlockingQueue、BlockingDeque 和 TransferQueue 接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.concurrent.BlockingQueue;public interface BlockingQueue <E > extends Queue <E > boolean offer (E element, long time, TimeUnit unit) throws InterruptedException void put (E element) E take () E poll (long time, TimeUnit unit) ... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.concurrent.BlockingDeque;public interface BlockingDeque <E > extends BlockingQueue <E >, Deque <E > void putFirst (E element) void putLast (E element) boolean offerFirst (E element, long time, TimeUnit unit) boolean offerLast (E element, long time, TimeUnit unit) E pollFirst (long time, TimeUnit unit) ; E pollLast (long time, TimeUnit unit) ; E takeFirst () ; E takeLast () ; ... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.util.concurrent.TransferQueue;public interface TransferQueue <E > extends BlockingQueue <E > void transfer (E element) boolean tryTransfer (E element, long time, TimeUnit unit) }
实现类 ArrayBlockingQueue:由数组结构组成的有界 阻塞队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package java.util.concurrent;public class ArrayBlockingQueue <E > extends AbstractQueue <E > implements BlockingQueue <E >, java .io .Serializable { ... final ReentrantLock lock; private final Condition notEmpty; private final Condition notFull; ArrayBlockingQueue<E>(int capacity) { this (capacity, false ); } ArrayBlockingQueue<E>(int capacity, boolean fair) { if (capacity <= 0 ) throw new IllegalArgumentException(); this .items = new Object[capacity]; lock = new ReentrantLock(fair); notEmpty = lock.newCondition(); notFull = lock.newCondition(); } ... public void put (E e) throws InterruptedException checkNotNull(e); final ReentrantLock lock = this .lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); insert(e); } finally { lock.unlock(); } } ... }
LinkedBlockingQueue:由链表结构组成的有界 阻塞队列
LinkedBlockingDeque:由链表结构组成的无界 双向阻塞队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import java.util.concurrent.LinkedBlockingQueue;import java.util.concurrent.LinkedBlockingDeque;LinkedBlockingQueue<E>() LinkedBlockingDeque<E>() LinkedBlockingQueue<E>(int capacity) LinkedBlockingDeque<E>(int capacity)
PriorityBlockingQueue:⽀持优先级排序的⽆界 阻塞队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.concurrent.PriorityBlockingQueue;PriorityBlockingQueue<E>() PriorityBlockingQueue<E>(int initialCapacity) PriorityBlockingQueue<E>(int initialCapacity, Comparator<? super E> comparator)
DelayQueue:使⽤优先级队列实现的⽆界 阻塞队列,支持延时获取元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import java.util.concurrent.DelayQueue;import java.util.concurrent.Delayed;DelayQueue<E extends Delayed> DelayQueue() interface Delayed long getDelay (TimeUnit unit)
应用场景:
缓存系统的设计:保存需要缓存的元素的有效期,使用线程循环地去查询队列;一旦获取到了元素,说明元素到期;
定时任务调度:保存需要执行的任务和执行时间点,一旦获取到了元素,说明当前时间点开始执行获取到的任务。
LinkedTransferQueue:由链表结构实现的 TransferQueue,⽆界 阻塞队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package java.util.concurrent;class LinkedTransferQueue ... public boolean tryTransfer (E e) return xfer(e, true , NOW, 0 ) == null ; } public void transfer (E e) throws InterruptedException if (xfer(e, true , SYNC, 0 ) != null ) { Thread.interrupted(); throw new InterruptedException(); } } ... }
SynchronousQueue:不存储元素 的阻塞队列,简单实现了阻塞机制
每一个 put() 操作都要等一个 take() 操作,否则便不能继续添加元素;
生产者可通过其直接将资源传递给消费者,中间不做任何保存;
非常适合传递性的场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package java.util.concurrent;class SynchronousQueue ... private transient volatile Transferer transferer; public SynchronousQueue () this (false ); } public SynchronousQueue (boolean fair) transferer = fair ? new TransferQueue() : new TransferStack(); } ... }
应用 生产者线程向队列插入元素,消费者线程从队列取出元素
worker(工作者)线程周期性地将中间结果存储到阻塞队列
其他 worker 线程移除中间结果作进一步修改
阻塞队列会自动做负载均衡
搜索或移除元素时,会等待队列变为非空
添加元素时,会等待队列有可用空间
会创建专门的线程去访问各对象,而不是各种有可能的工作线程
线程安全集合 JDK concurrent 包下还有许多线程安全的集合类,使用起来跟普通的名字对应的集合类几乎没有区别。
它们的使用特点是:size() 不必在常量时间内操作
确定集合的当前大小需要遍历
集合返回弱一致性(weak consistent)的迭代器,因此不一定反映出构造后所有的修改
不会抛出 ConcurrentModificationException
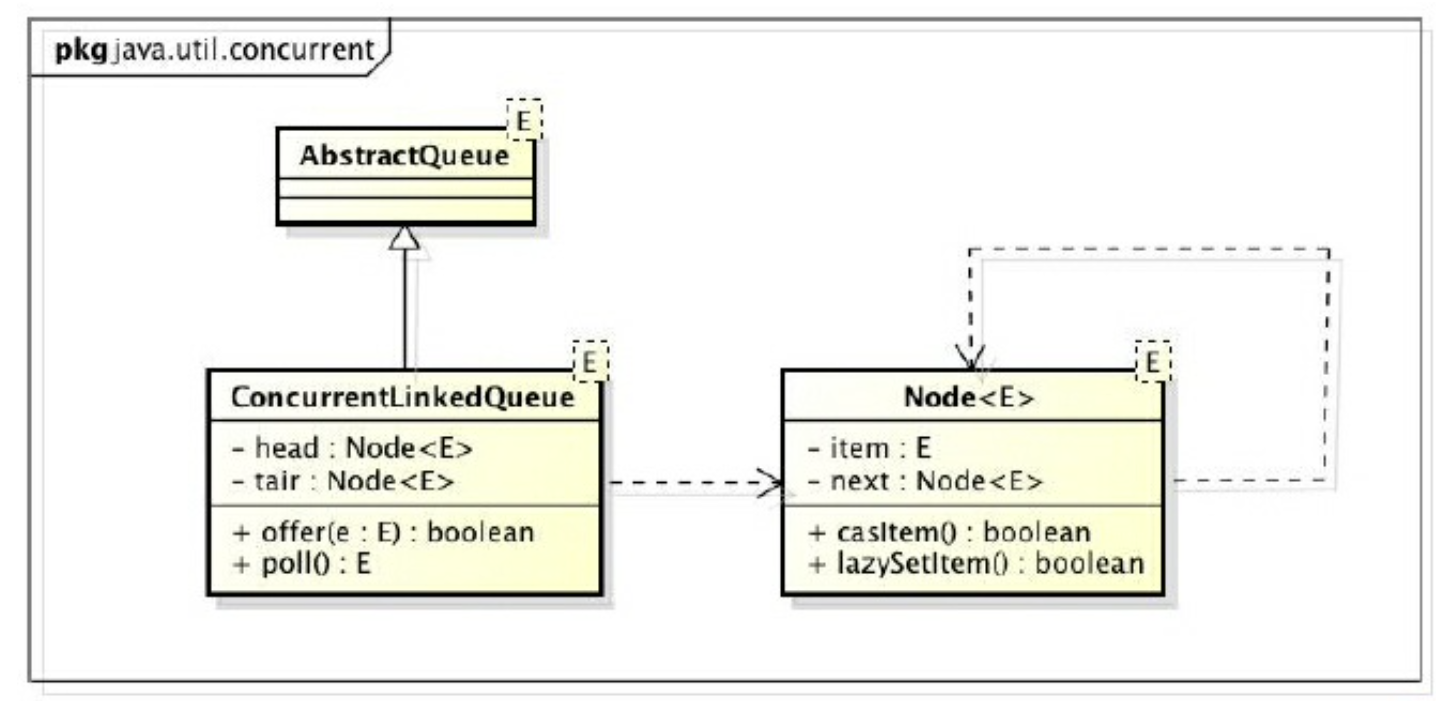
ConcurrentLinkedQueue 跟阻塞队列不同的是,ConcurrentLinkedQueue 采用自旋 CAS 的方式实现线程安全操作。
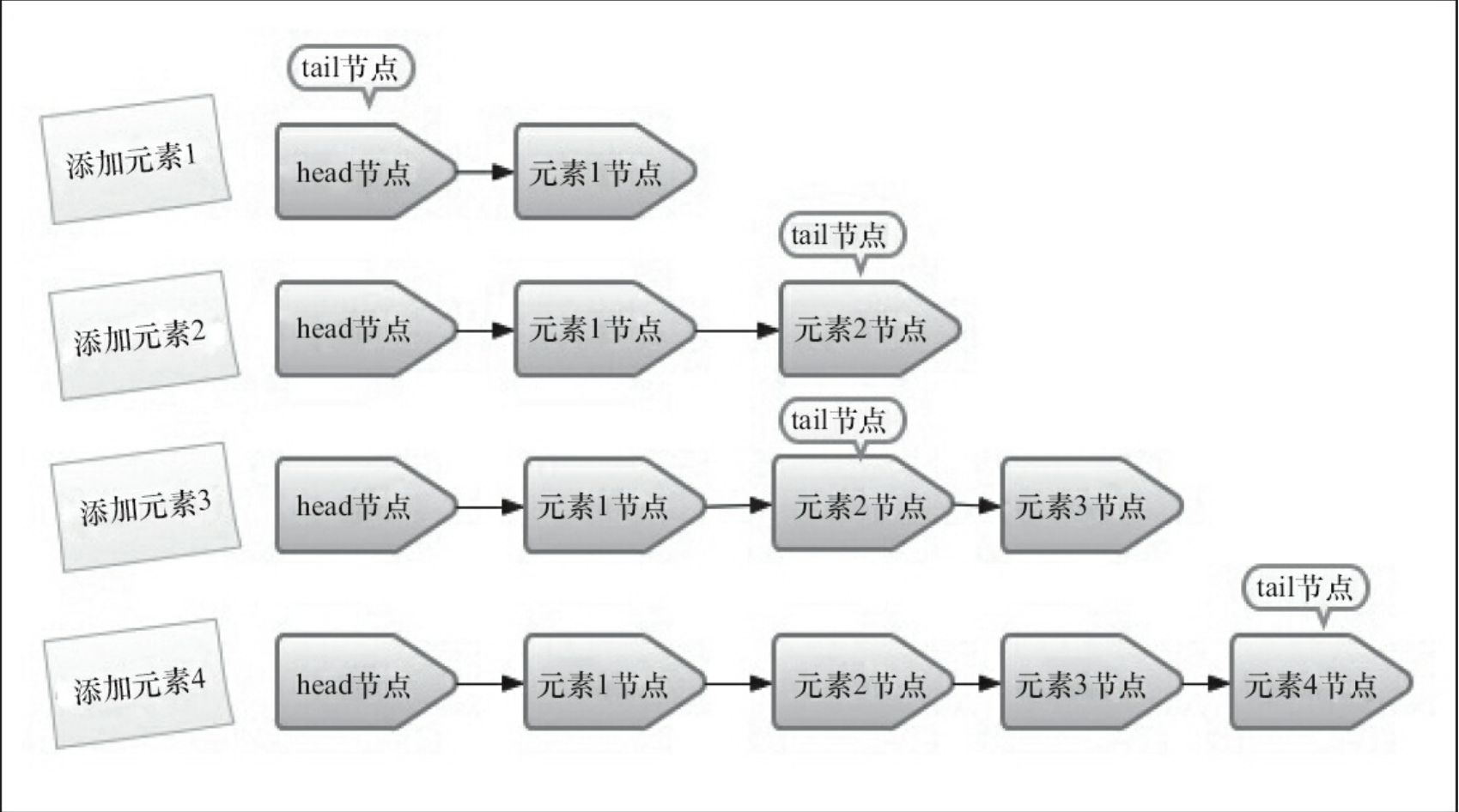
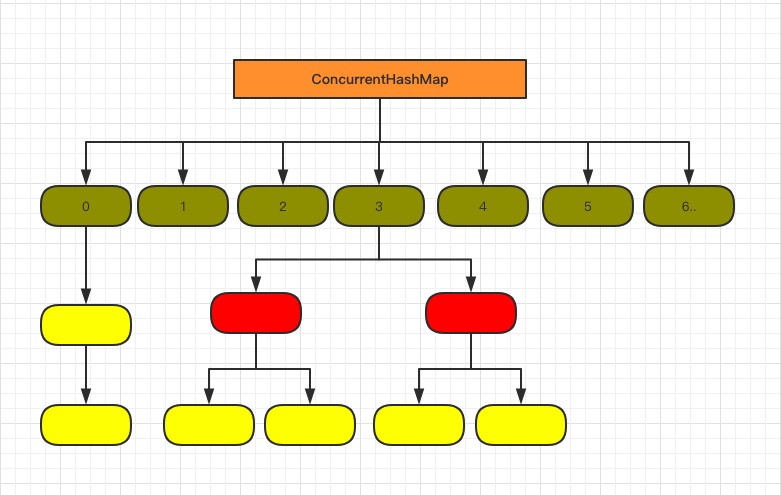
入队操作
上图为新创建的队列每添加一个节点时所留的快照。
新入队的元素永远都是被添加到队列的尾部,成为队列的尾节点;需要注意的是,tail 节点不总是尾节点 。
如 tail 节点的 next 不为空,有新元素入队后,tail 节点会指向新元素(tail 成为尾节点);
如 tail 节点的 next 为空,新元素入队后,tail 节点的 next 会指向新元素(tail 的 next 成为尾节点);
因为队列刚刚创建的时候 head = tail,第一个元素添加进去后,head 和 tail 的 next 节点都会指向第一个元素。
以上为单线程操作时的基本情况;如果是多线程操作的话,情况会更加复杂,因为会存在多个线程插队的情况。
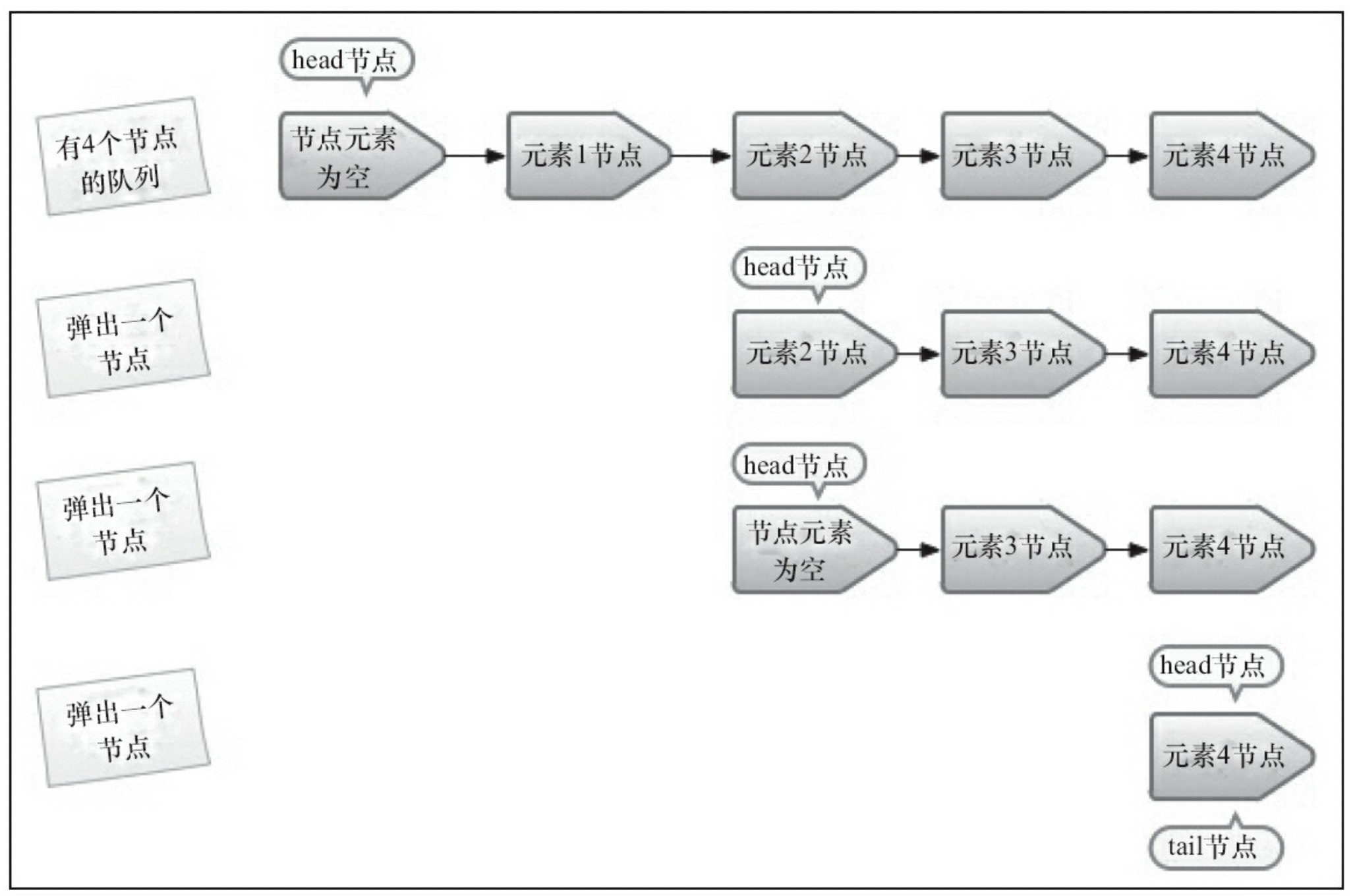
出队操作
上图为队列每移除一个元素时所留的快照。
与入队方法类似的是,并不是每次出队的时候都更新 head 节点:当 head 节点有元素值时,直接弹出元素,不更新 head 节点;head 节点没有元素时才更新 head 节点。
下面基于 Java 7 的实现来看看 ConcurrentLinkedQueue 的关键代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 package java.util.concurrent;public class ConcurrentLinkedQueue private static class Node <E > volatile E item; volatile Node<E> next; Node(E item) { UNSAFE.putObject(this , itemOffset, item); } boolean casItem (E cmp, E val) return UNSAFE.compareAndSwapObject(this , itemOffset, cmp, val); } void lazySetNext (Node<E> val) UNSAFE.putOrderedObject(this , nextOffset, val); } boolean casNext (Node<E> cmp, Node<E> val) return UNSAFE.compareAndSwapObject(this , nextOffset, cmp, val); } private static final sun.misc.Unsafe UNSAFE; ... } ... private transient volatile Node<E> head; private transient volatile Node<E> tail; public ConcurrentLinkedQueue () head = tail = new Node<E>(null ); } ... final void updateHead (Node<E> h, Node<E> p) if (h != p && casHead(h, p)) h.lazySetNext(h); } final Node<E> succ (Node<E> p) Node<E> next = p.next; return (p == next) ? head : next; } private static final int HOPS = 1 ; public boolean offer (E e) if (e == null ) throw new NullPointerException(); final Node<E> n = new Node<E>(e); retry: for (;;) { Node<E> t = tail; Node<E> p = t; for (int hops = 0 ; ; hops++) { Node<E> next = succ(p); if (next != null ) { if (hops > HOPS && t != tail) continue retry; p = next; } else if (p.casNext(null , n)) { if (hops >= HOPS) casTail(t, n); return true ; } else { p = succ(p); } } } } public E poll () Node<E> h = head; Node<E> p = h; for (int hops = 0 ; ; hops++) { E item = p.item; if (item != null && p.casItem(item, null )) { if (hops >= HOPS) { Node<E> q = p.next; updateHead(h, (q != null ) ? q:p); } return item; } Node<E> next = succ(p); if (next == null ) { updateHead(h, p); break ; } p = next; } return null ; } ... }
注:
offer() 主要做了两件事,一是找到尾节点,二是 CAS 设置新的尾节点,失败了就不断重试;尾节点可能是 tail 节点,也可能是 tail 的 next 节点;
与之相类似:头节点可能是 head 节点,也可能是 head 的 next 节点;
HOPS 的阈值判断对应的是上文提到的“tail 节点不总是尾节点 / head 节点不总是头节点 ”的实现。
为啥非得要用 HOPS 去判断是否应该更新尾节点和设置 tail 节点?像下面这样写得简单点不好吗:1 2 3 4 5 6 7 8 9 10 public boolean offer (E e) if (e == null ) throw new NullPointerException(); Node<E> n = new Node<E>(e); for (;;) { Node<E> t = tail; if (t.casNext(null , n) && casTail(t, n)) { return true ; } } }
tail 节点距离尾节点越长,每次 offer 入队 CAS 操作更新 tail 节点的次数越少,但定位尾节点所需的时间就越长。
Java 8 的实现与 Java 7 的实现相差不是很大。
ConcurrentHashMap ConcurrentHashMap 不仅是 HashMap 的线程安全实现,而且更高效。因为:
在多线程环境下使用 HashMap,因其不是线程安全的类,容易发生死循环:HashMap 扩容的时候会 rehash,内部类 Entry 列表会形成环形的数据结构,next 节点就一直不为空了。
如果线程安全的旧集合 Hashtable:Hashtable 的同步(synchronized)都是方法级别的,加锁的时候整个对象都被锁住了,竞争激烈的时候效率低下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package java.util.concurrent;public class ConcurrentHashMap <K ,V > extends AbstractMap <K ,V > implements ConcurrentMap <K ,V >, Serializable ... public ConcurrentHashMap<K,V>(int initialCapacity, float loadFactor, int concurrencyLevel) { ... } public ConcurrentHashMap<K,V>(int initialCapacity, float loadFactor) { ... } public ConcurrentHashMap<K,V>(int initialCapacity) { ... } public ConcurrentHashMap<K,V>() { ... } ... V putIfAbsent (K key, V value) boolean remove (K key, V value) boolean replace (K key, V oldValue, V newValue) ... }
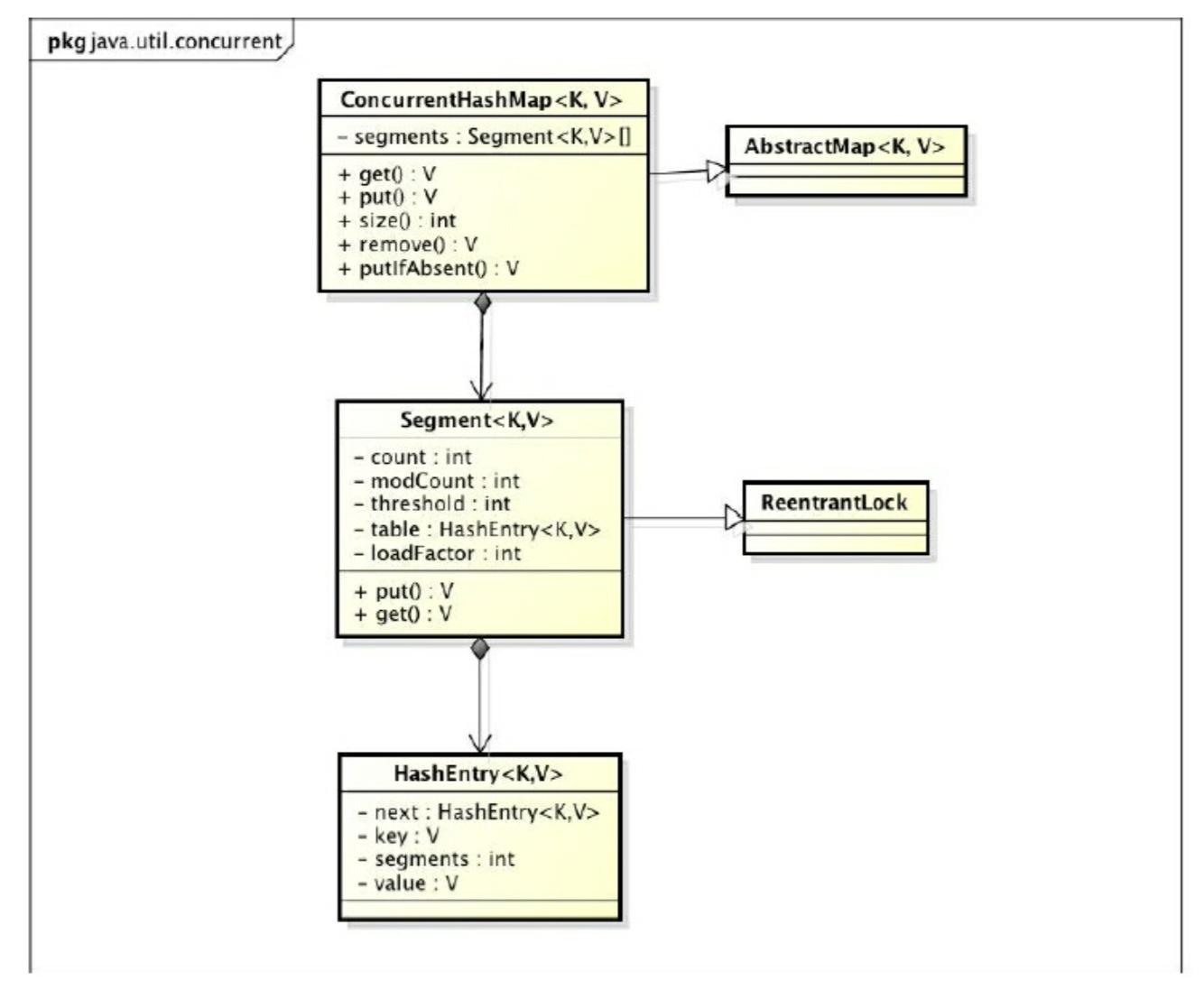
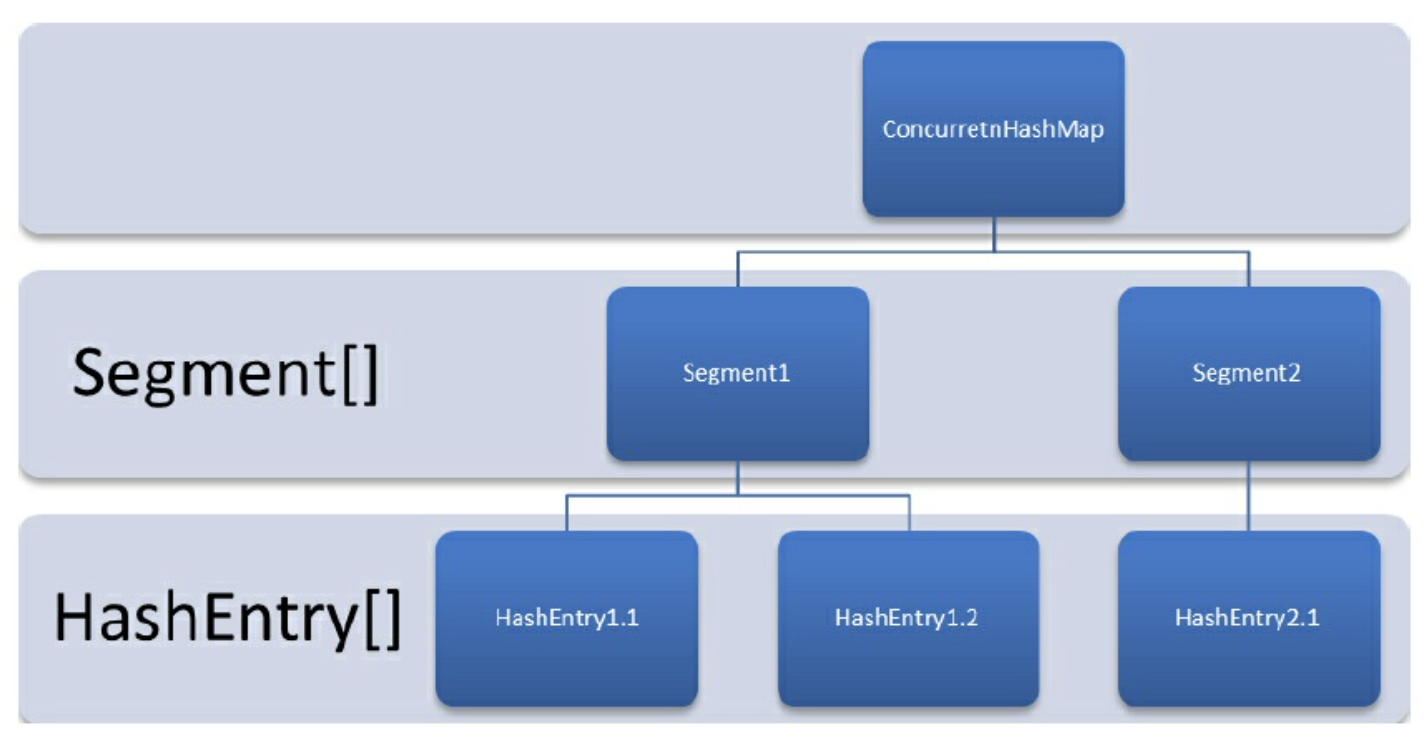
Java 7 & before 的实现 分段锁 实现并发更新,提升访问效率。其底层采用了数组 + 链表 的实现方式。
核心的静态类如下:
Segment:继承 ReentrantLock 充当锁的角色,每个 Segment 对象通过数组维护一个键值对的链表;
一个 Segment 的结构和一个 HashMap 是差不多的;
因此 Segment 为分段锁 的实现
HashEntry:键值对,map 的基本存储单元
要对 HashEntry 进行修改的话,需要先获取管理它的 Segment 的同步状态
每个 ConcurrentHashMap 对象维护一个 Segment 数组,每个 Segment 对象扩展一个可重入锁,分别只锁对应散列值的数据,一定程度上提高了并发效率。
基本层级如下:
相关代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 package java.util.concurrent;public class ConcurrentHashMap <K ,V > extends AbstractMap <K ,V > implements ConcurrentMap <K ,V >, Serializable ... static final int DEFAULT_INITIAL_CAPACITY = 16 ; static final float DEFAULT_LOAD_FACTOR = 0.75f ; static final int DEFAULT_CONCURRENCY_LEVEL = 16 ; ... static final class HashEntry <K ,V > ... volatile V value; volatile HashEntry<K,V> next; ... } ... static final class Segment <K ,V > extends ReentrantLock implements Serializable ... transient volatile HashEntry<K,V>[] table; ... } ... public ConcurrentHashMap<K,V>(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0 ) || initialCapacity < 0 || concurrencyLevel <= 0 ) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrentLevel = MAX_SEGMENTS; int sshift = 0 ; int ssize = 1 ; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1 ; } this .segmentShift = 32 - sshift; this .segmentMask = ssize - 1 ; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1 ; Segment<K,V>[] s0 = new Segment<K,V>(loadFactor, (int )(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); this .segments = ss; } public ConcurrentHashMap<K,V>(int initialCapacity, float loadFactor) { this (initialCapacity, loadFactor, DEFAULT_CONCURRENCY_LEVEL); } public ConcurrentHashMap<K,V>(int initialCapacity) { this (initialCapacity, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); } public ConcurrentHashMap<K,V>() { this (DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL); } ... public int size () ... try { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0 ; j < segments.length; ++j) ensureSegment(j).lock(); } sum = 0L ; size = 0 ; overflow = false ; for (int j = 0 ; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null ) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0 ) overflow = true ; } } if (sum == last) break ; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0 ; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; } public V get (Object key) Segment<K,V> s; HashEntry<K,V>[] tab; int h = hash(key); long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && (tab = s.table) != null ) { for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile (tab, ((long )(((tab.length - 1 ) & h)) << TSHIFT) + TBASE); e != null ; e = e.next) { K k; if ((k = e.key) == key || (e.hash == h && key.equals(k))) return e.value; } } return null ; } ... private int hash (Object k) ... } ... private Segment<K,V> segmentForHash (int h) long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u); } ... }
Since Java 8 的实现 与 Java 7 最大的一点不同,是 Java 8 的 ConcurrentHashMap 放弃了分段锁的实现 Segment ,改用 Node + CAS + synchronized 保证并发安全:
直接用原 Segment 类中的 table 数组 存储键值对;
如果定位到 table 数组上的 Node 为空,则采用 CAS 操作写入数据;
如果不为空,则使用 synchronized 锁住链表头节点 再写入数据。
同一个桶里面 HashEntry 的 Node(键值对)的组织形式会经历从链表 到红黑树 的转变:
当 HashEntry 对象组成的链表长度超过 TREEIFY_THRESHOLD 时:链表转换为红黑树;
更像是 Java 8 中的 HashMap 实现
问题:短时间内插入大量数据至 ConcurrentHashMap 首先我们要明确,插入数据的性能损耗点,在于扩容操作 和锁的争夺 。
第一,通过配置合理的容量大小和扩容因子,尽可能减少扩容的发生;spread() 进行预处理,将存在 hash 冲突的数据放到一个组中,每个组使用单线程 put(),从而保证锁停留在偏向锁级别,不会升级。
ConcurrentSkipListMap 1 2 3 4 5 6 7 8 9 10 11 12 13 import java.util.concurrent.ConcurrentSkipListMap;ConcurrentSkipListMap<K, V>() ConcurrentSkipListMap<K, V>(Comparator<? super K> comp)
其它线程安全集合 ConcurrentSkipListSet
线程安全的有序集合
可以视为 TreeSet 的同步实现,实现了 NavigableSet 接口
1 2 3 4 5 6 7 import java.util.concurrent.ConcurrentSkipListSet;ConcurrentSkipListSet<E>() ConcurrentSkipListSet<E>(Comparator<? super E> comp)
CopyOnWriteArrayList
先说一下概念:CopyOnWrite , COW,复制再写入
在添加元素的时候,先将原集合列表复制一份,再添加新的元素
只适合读多写少 的情况
该集合类参考了延时懒惰策略和读写分离的思想
在读取时,多线程正常读取内容
写内容时,将当前对象进行复制,往新的对象进行修改 ,完成后再将引用指向新的对象
将读写分离,属于读写锁的实现(读同步,写互斥)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public boolean add (E e) ReentrantLock lock = this .lock; lock.lock(); boolean added; try { Object[] elements = this .getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1 ); newElements[len] = e; this .setArray(newElements); added = true ; } finally { lock.unlock(); } return added; } private E get (Object[] a, int index) return a[index]; } public E get (int index) return this .get(this .getArray(), index); }
类似的实现:CopyOnWriteArraySet
1 2 3 4 5 public boolean addIfAbsent (E e) Object[] snapshot = this .getArray(); return indexOf(e,snapshot, 0 , snapshot.length) >= 0 ? false : this .addIfAbsent(e,snapshot); }