乙巳年伊始,DeepSeek R1 的开源犹如一响惊雷,震动了寰宇大地,由 GPT 引领的大模型演进、自然语言处理、神经网络算法乃至深度学习、全图谱人工智能领域的热度再次被推上一个新的高度。新一年几乎掀起了全民学 AI 的热潮,似乎预示着颠覆性变革的到来。
硕士生涯的时候学习过 AI 基础,加上本人的风格就是在遇到一个新风口的时候喜欢探究其原理,于是乎,想借助本文简单拟一个 DeepSeek,乃至整个大模型演进的科普文章,简单阐述原理,以便在日后的工作中能够根据基础知识举一反三、触类旁通、事半功倍。
我们先从 DeepSeek 的基础 —— 深度学习简单展开,然后聊一下 DeepSeek 的竞对 GPT,再通过对比引出 DeepSeek 的精妙之处。
深度学习
普通的神经网络
一个基础的神经网络包括三层:输入层、隐藏层和输出层
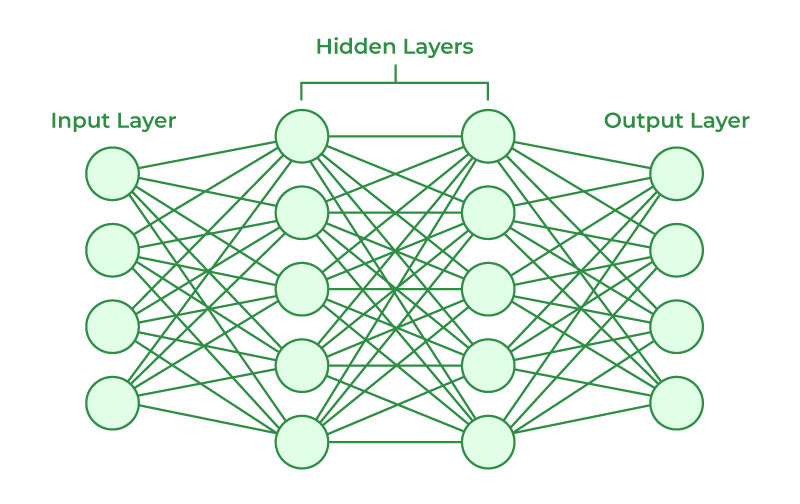
- 输入层自身就是一层对接输入数据的神经网络;
- 输出层输出整个神经网络的计算结果;
- 隐藏层涉及到功能执行的参数和计算过程,不直接暴露,即“黑盒”
“黑盒”的实现有很多,最简单的是单层感知机(Single-layer Perceptron),用于二分类任务的线性分类器(binary classifier),无法处理非线性问题;其它常用的神经网络包括:
- CNN(Convolutional Neural Network) 卷积神经网络
- GNN(Graph Neural Network) 图神经网络
- RNN(Recurrent Neural Network) 循环神经网络
输入预处理 pre-processing
并不是所有的数据,都能通过隐藏层输出符合预期的结果;隐藏层往往对输入有明显的特征要求,所以对输入数据进行预处理非常重要。
激活函数 activation function
激活函数是神经网络的重要特征,决定了网络中的一个神经元是否应该被激活:神经元接收的信息与给定的条件有关。
激活函数对输入信息进行非线性变换,变换后的输出会作为下一个神经元的输入 —— 这个变换非常重要,如果没有激活函数,输出永远都是基于输入的线性转换,极有可能无法收敛于我们的期望结果。
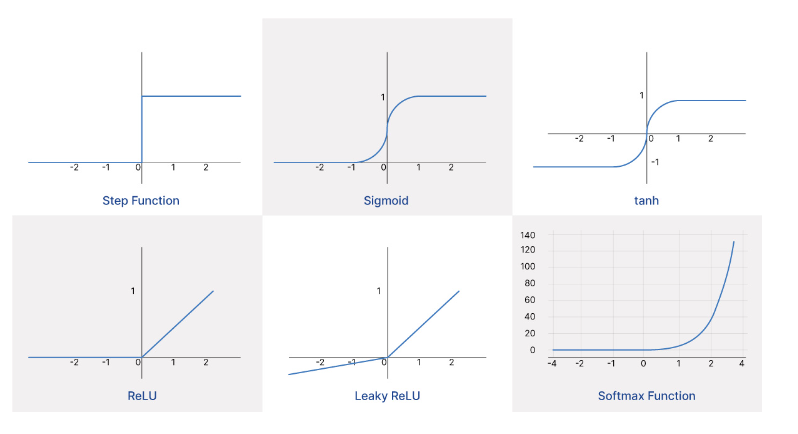
因此激活函数存在于输入层、隐藏层和输出层的所有神经元,简单的激活函数有:
sigmoid: 适合输出预测概率,存在梯度消失(函数图像的两端,即输入值很大或很小的情况下,导数接近于 0 —— 意味着在网络的深层,由于多次连乘的影响,梯度会变得极小,导致演进停滞不前)可能;tanh: 适合输出预测概率,存在梯度消失可能;relu: 无梯度消失,几乎可以到处使用,但表现能力较弱,一般只用于隐藏层;softmax: 目前最常用,多用于多分类问题,存在梯度消失可能
损失函数 loss function
损失函数用来度量模型的预测值 f(x) 和真实值 Y 的差异程度,是一个非负实值函数:损失函数越小,模型越强壮。
损失函数主要用在模型的训练阶段:
- 每个批次的训练数据被送入模型后,通过前向传播(forward pass)输出预测值;
- 损失函数根据预测值算出和真实值的损失值,通过反向传播(backward pass)更新模型的各个参数,以图降低后续的损失值;
- 由此往复,使模型预测值向真实值方向收敛,达到学习目的
因为神经网络乃至 AI 中有两个不同的场景:训练和推理
- 推理的计算过程仅包括前向传播:因为整个神经网络模型已经准备完毕,用户输入数据后可以获得相对稳定且准确的结果;
- 训练的计算过程都包括:因为此时的神经元参数为 0 或其它参数值,用户输入数据后并不能获得准确结果,需要根据损失函数的损失值,通过监督(supervised learning)或无监督(unsupervised learning)学习等进行反向传播,更新参数值,并不停地进行迭代,使模型可用于推理
因此训练的计算量更大,内存访问更多,过程更复杂。
参数更新的方式也很简单:求导,获得梯度,以梯度的更新向合理的参数逼近。梯度更新注意避免两种情况:
- 梯度消失:梯度为 0 或接近于 0,后果是参数无更新,或更新极小,导致训练缓慢甚至停止(所谓的“神经元无法有效传导”);
- 梯度爆炸:梯度过大,参数更新过于激烈,导致损失函数一直抖动,无法收敛
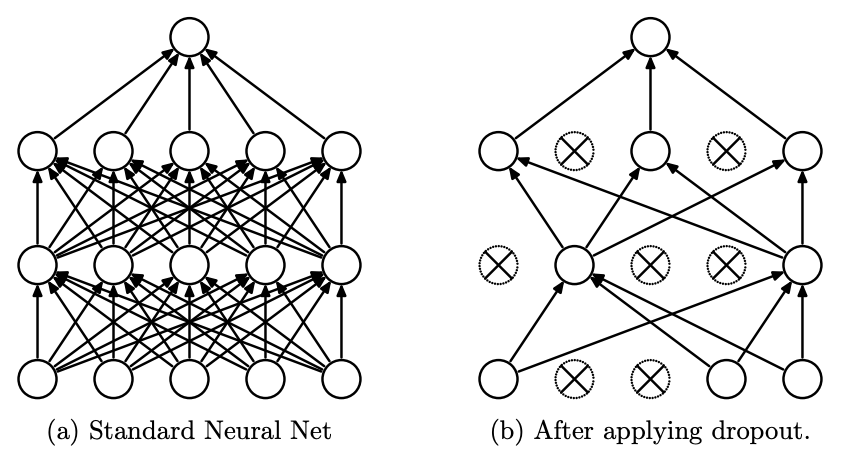
解决过度拟合 overfitting
类似于数据挖掘的经典问题:避免陷入局部最优解。过度拟合体现在:模型在训练集上损失值较低,预测准确率较高;但在测试集上损失值大,预测准确率低,得到的模型基本不可用。
常用的有一种缓解过度拟合的方法:dropout,要求所有神经元带上一个停止工作的概率 p,在前向传播的时候,某几个神经元会有一定的概率 p 停止工作,使模型不太依赖某些局部特征,更具有泛化性。
NLP
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要方向,大模型的本身也是 NLP 的一部分,在 GPT 实现多模态之前,输入也是文本语言。
RNN
循环神经网络 RNN 是最早用于 NLP 的“黑盒”构型,不仅依赖当前输入,还取决于先前输入的中间结果。
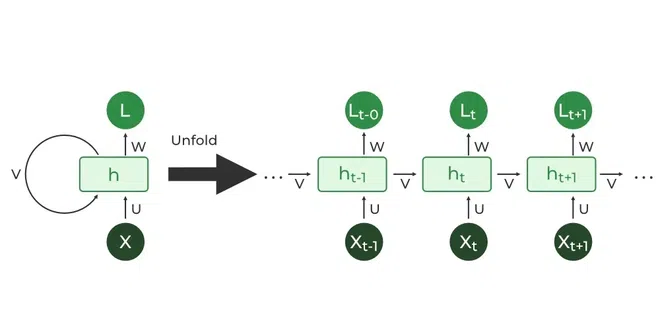
因此 RNN 可以通过先前输入的中间结果影响当前输入的结果,与 NLP 的基本问题(根据先前的文本推断下文)高度吻合;故同样类型的推理(训练)任务也可以用 RNN 处理。
LSTM
Long Short-Term Memory,长短期记忆属于一种特殊的 RNN 网络,主要解决了长序列训练过程中的梯度消失和梯度爆炸问题,在更长序列中有更好的表现。
相比于 RNN 只有一个传递状态,LSTM 有两个传递状态,cell state 和 hidden state:
- 传递的 cell state 改变得很慢,通常的输出是上一状态的 cell state 加上一些数值;
- hidden state 在不同的节点下往往有很大区别
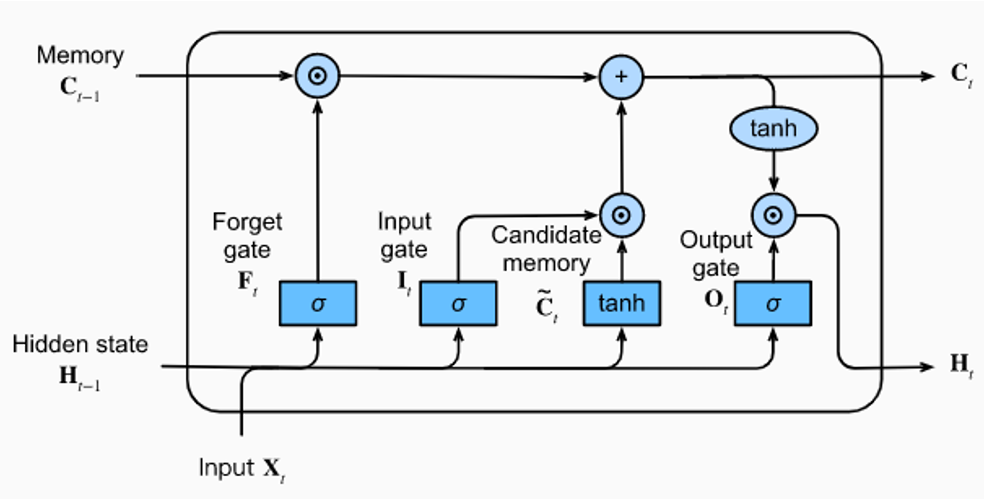
因为 cell state 的存在,LSTM 对长期信息的记忆更久。
Encoder-decoder
以上情况我们均考虑输入输出序列等长的情况,然而实际生活中大量存在输入输出序列长度不等的情况,如机器翻译、语音识别、问答系统等。
Encoder-decoder 能够完成从一个可变长序列至另一个可变长序列的映射,属于机器模型(Machine Translation)的产物。
它的基本思想非常简单:使用一个 RNN 读取输入的句子,将整个句子的信息“压缩”到一个固定维度的编码中;再使用另一个 RNN 读取这个编码,将其“解压”为目标语言的一个句子(seq2seq)。由此的“压缩”和“解压”一来一回,就组成了一个编码器(Encoder)和解码器(Decoder),大大提高灵活性。
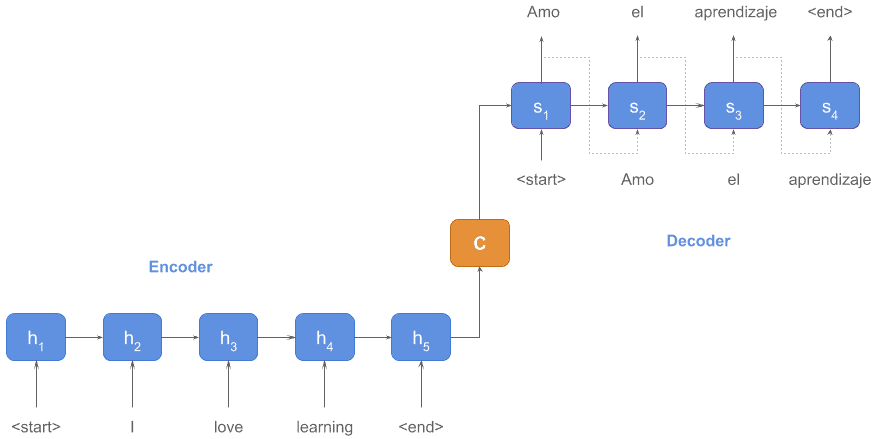
但是它的局限性也很明显:encoder 和 decoder 之间的唯一联系是一个固定的语义编码 C,即 encoder 要将整个序列的信息压缩到一个固定长度变量中。
- 一是语义编码 C 可能无法完全表示整个序列的信息;
- 二是先输入到网络的内容携带的信息会被后输入的信息覆盖,输入序列越长,现象越严重
这两个弊端会导致解码的时候,decoder 一开始就没有获得序列足够多的信息,导致解码准确率不高。
为了解决这两个弊端,大牛们引入了著名的注意力(attention)机制。
Attention
深度学习中的注意力机制借鉴了人类的注意力思维方式。在最早提出 attention 的论文中,attention 是作为一个中间层出现的,位于 encoder 和 decoder 之间,跟原来的语义编码类似。
我们可以从两个方面简单理解 attention:
- 每次处理(每次只注意)一个窗口的输入数据;
- 注重数据之间的关联性
在 attention 中,语义编码不再是固定维度的编码,也不是输入序列的直接编码,而是由各个元素按照重要程度加权求和得到的值:
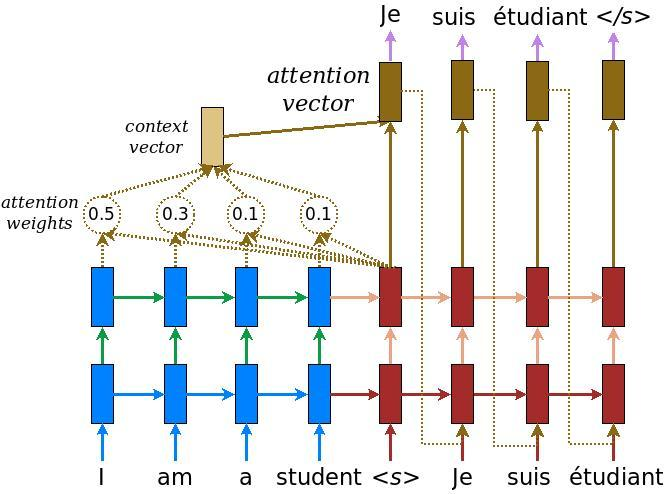
总体而言,attention 机制可以分为四步:
- 点积(向量在目标向量上的投影):值越大说明关联度越大,0 说明没有关联度
- 打分:第一步的加强,获得一个更加贴合需要的匹配分布
- softmax;基于前两步输出做重新分布;
- 点积
目前业界存在很多不同的分类方法,其中使用比较多的一个是 soft-attention,另一个是 transformer 使用的 self-attention。
Transformer
讲到这里终于可以展开聊聊这块大模型的基石了。由于其良好的性能,导致目前大模型的发展就是堆 transformer,算力的核心就是 transformer 的各个机制。
虽然 attention 机制解决了 Encoder-decoder 输入输出必须等长的问题,但本质还是在 Encoder-decoder 上雕花,执行顺序是循环顺序,也就是说,只能从左到右或者从右到左计算,这样子就存在另外的问题:
- 时间片 t 的计算依赖 t - 1 时刻的计算结果,限制了模型的并行能力,训练以及推理的过程慢;
- 尽管 LSTM 多个门和双状态输入的机制已经从一定程度上缓解了长依赖的问题,但缓解不意味着解决,对于特别长的依赖,LSTM 依旧无能为力,意味着顺序计算过程中信息还是会流失
2017 年,重量级的 attention 论文发布,摒弃了传统的 NN 构型,只需要采用 attention 即可完成任务,同时 Encoder-decoder 被替换 —— 这就是著名的 Transformer 机制。
架构
Transformer 沿用了 Encoder-decoder 的架构,但是将原来依赖于 RNN、LSTM 的 encoder 和 decoder 采用 attention 机制完全改写。
改写之后,一个完整的 transformer 由 encoder block 和 decoder block 两部分组成:
- 每个 block 中的 encoder 由 self-attention 和 FNN(Feedforward Neural Network,前馈神经网络) 两部分组成;
- 每个 block 中的 decoder 同样包括 FNN,另外还有两个 self-attention,分别用于计算输入和输出的权值:
- Masked attention: 当前翻译和已经翻译的前文之间的关系,获取特征向量;
- Encoder-decoder self-attention: 当前翻译和编码的特征向量之间的关系
![]()
encoder 和 decoder 都是以滑动窗口的方式分批次处理长文本的。
用户输入经过 transformer 得到了输出结果,是一个完整的端到端的流程。
核心:self-attention
与传统 attention 的区别:
- 传统 attention 基于 source 端和 target 端传递的大变量 hidden state 做计算,得到的结果代表了 source 端的每个词语 target 端每个词之间的依赖关系;
- 而 self-attention 分别从 source 和 target 两端进行:
- 先捕捉 source 端或 target 端自身的词与词之间的依赖关系;
- 再将 source 端得到的 self-attention 加入到 target 端得到的 attention,捕捉 source 端和 target 端词与词之间的依赖关系
![]()
self-attention 明确了三种不同的向量:查询向量 Q(query)、键向量 K(key)、值向量 V(value)。
self-attention 比传统的 attention 机制效果要好,因为传统 attention 忽略了 source 或 target 端词与词之间的依赖关系;而 self-attention 不仅仅得到 source 和 target 端词与词之间的依赖关系,同时还可以有效获得 source 端或 target 端自身词与词之间的依赖关系。
在 self-attention 中:
- encoder 的输入为 inputs 结合 positional encoding,decoder 的输入为 outputs 结合其 positional encoding;
- 最简单的 self-attention 由一个 encoder block 和一个 decoder block 组成,每个 block 中的 attention 都是 Multi-head attention,分别由多个结构类似的 Scaled Dot-product attention 组成。
Scaled Dot-product attention,缩放点乘注意力机制,跟上面讲的 attention 机制没啥区别,只是除去了维度的平方根,相对于 softmax 参数值较大时产生梯度消失的时候,可以使值的分布重新均匀,有效缓解梯度消失(关于梯度的计算,attention 机制的计算尤为复杂,本文先按下不表)。
回过来讲多头注意力机制:简单来说,就是多个 scaled dot-product attention 的结果进行连接后再次点乘权重;每个 scaled dot-product attention 称为一个“头”(head)。
FNN
全连接层,包括第一层的非线性激活函数 relu 和第二层的线性激活函数:
FNN 的存在变换了 attention output 的空间,增加了模型的表现能力;去掉 FNN 也可以,但是效果会变差。
输入预处理
Transformer 的输入预处理包括两点:masking 机制、位置编码
Masking 机制有两类:用于处理非定长序列的 padding mask,和用于防止标签泄露的 sequence mask。
- padding mask 针对非定长序列切割成长短不一的文本 batch 后,针对长度不足的样本使用特殊字符(如 \
- sequence mask 用于在同时使用上下文信息的机制中遮盖要预测的标签信息,不让模型“提前看到”
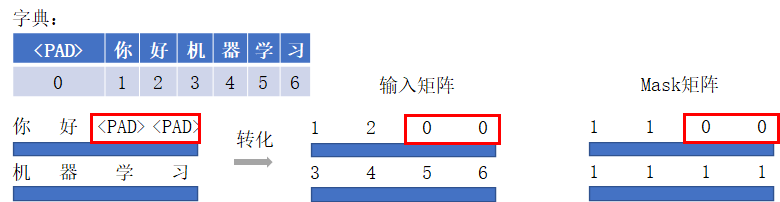
padding mask 常常用在最终结果输出、损失函数计算等一切受样本实际长度影响的计算,或者不需要无用 padding 参与计算的时候。
再来说说位置编码(Position Encoding)。位置编码主要拿来确定句子中单词的语序信息:
- 对于任何一门语言,单词在句子里面的位置是十分重要的。一个单词在句子里面的排列顺序不同,整句话的意思就可能发生偏差;
- Transformer 抛弃了 RNN、CNN 这些顺序结构为基础的神经网络,以 attention 取而代之,词序就会丢失,模型就无法知道每个词在句子里面的相对和绝对位置
优势及后续发展
Transformer 在 NLP 的发展中优势巨大的原因是:
- 模型并行度高,使训练时间大为降低;
- 可以直接捕获序列中的长距离依赖关系,不仅是输入与输出之间词与词的关系,也包括输入与输出本身词与词之间的依赖;
- 可以产生更具解释性的模型
针对 transformer 吃内存等一系列局限性,业界有了以下优化:
- 多查询注意力机制(Multi-Query Attention, MQA,用于 GPT-4):只需要每个 head 有独立的 Q,K V 均共享,由此减少了需要加载的矩阵内存量;
- ByteTransformer:因为可变长的序列非常普遍,切割成 batch 的时候会产生巨量没有意义的 padding,造成资源浪费;byteTransformer 解决了这个问题,不仅减少了内存应用,还维持了性能;
- SparseTransformer:针对图像和视频等更高密度计算,运用稀疏矩阵进行的 transformer 优化
- Decoder-only transformer:只保留了 decoder block 的 transformer,将原本需要翻译的文本(encoder 输入)和翻译完成的上文(decoder 输入)合并作为一个整体输入来处理(target-specific embedding 替代 encoder 的输入)。
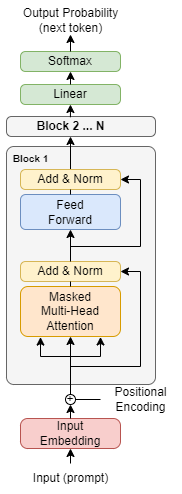
⚠️ 注意:现在的 LLM 都是 decoder-only 的架构。
encoder-decoder 需要在一定量的标注数据上做 multitask finetuning 才能激发最佳性能;而 decoder-only 在没有任何 tuning 数据的情况下,zero-shot(零样本学习)表现最好 —— 目前 LLM 训练还是基于大规模语言材料进行自监督学习,zero-shot 具有极大便利性。
预训练
Pre-trained Models,预训练,即先在一个基础数据集上进行任务训练,生成一个基础网络,然后将学习到的特征进行微调,或者迁移到另一个目标网络上,用来训练新目标任务。
预训练是在大量常规数据集上学习数据里面的“共性”,然后在特定领域的少量标注数据学习“特性”。因此模型只需要从“共性”出发,学习特定任务“特性”即可。优势在于:
- 预训练模型的参数从大量常规数据集中得来,比起单纯在自己的数据集上从头开始训练,进度会更快;
- 预训练模型更好地学到了数据中的普遍特征,比起在自己的数据集上从头开始训练会有更好的泛化效果
怎么训练?这里就涉及到了一个重要的概念:
有监督学习与无监督学习
有监督学习(Supervised Learning)有明确的目的,也明确知道期待的结果;因为训练过程中数据集有明确标签,所以中间计算错误了能直接判断出来,结果很容易被量化和衡量。
无监督学习(Unsupervised Learning)没有明确的目的,无法提前知道结果,因此也不完全明确训练数据的关系。其目标是找到数据集的底层结构,根据相似性对这个数据集进行内在关联和区分。
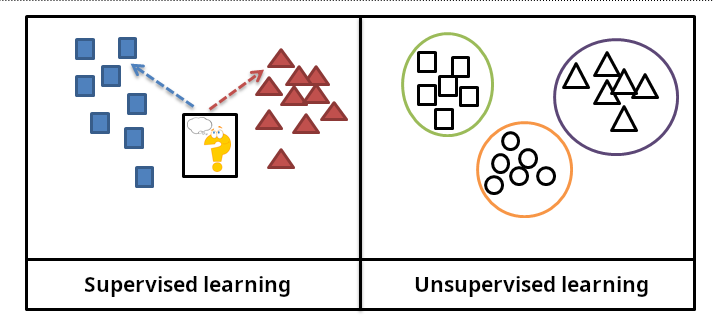
早期训练以有监督学习为主,但模型泛化性较差;而无监督学习有着更好的泛化效果,有助于从数据中找到“有用的见解”,思考方式也更接近于人类的思考方式,所以无监督学习的潜在能力更强。
基于训练集中数据的类型(和测试集类型是否相同),又可以分成以下的不同方式:
| 类型 | 中文名词 | 训练集中与测试集同类别的样本数量 | 例子 |
|---|---|---|---|
| Traditional learning | 传统学习 | >>1 | 测试集为一张斑马跑步的照片,训练集中有海量(比如百万的量级)有关斑马的标注的数据,有斑马休息的、几只斑马在一起的、斑马吃草的等等,也很可能有斑马各种跑步姿势的照片 |
| Few-shot learning | 少样本学习 | >1 | 测试集为一张斑马跑步的照片,训练集中有少量(比如数十的量级)有关斑马的标注的数据,有斑马休息的、几只斑马在一起的、斑马吃草的等等,极少和测试任务的照片相似 |
| One-shot learning | 单样本学习 | =1 | 测试集为一张斑马跑步的照片,训练集中只有一张有关斑马的标注的数据,例如一张斑马休息的照片 |
| Zero-shot learning | 零样本学习 | =0 | 测试集为一张斑马跑步的照片,训练集中没有有关斑马的标注的数据 |
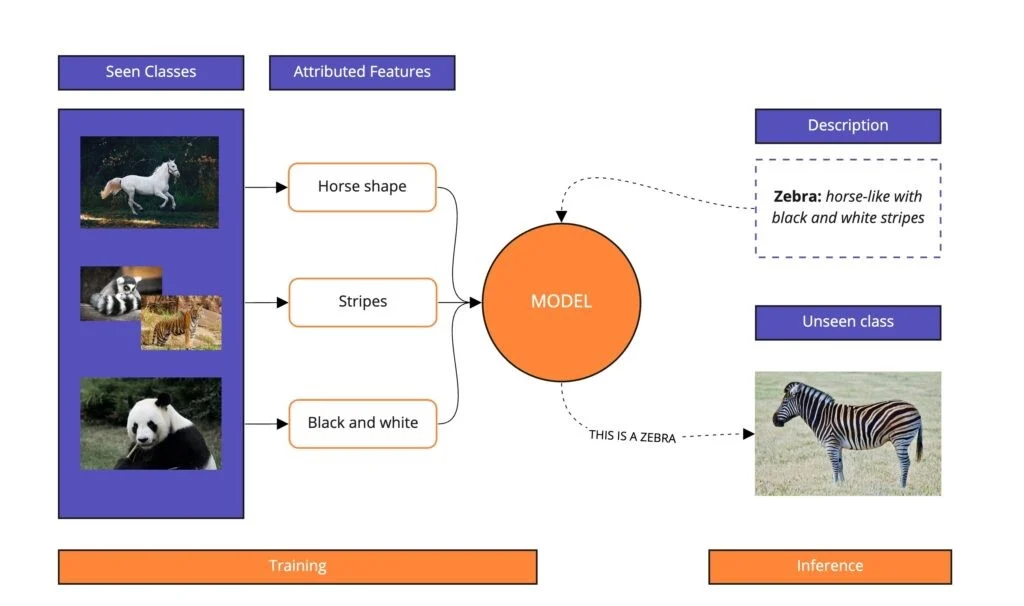
很容易看出,zero-shot 泛化性更强,而传统方法已经基本不在用了。
自监督学习
Self-supervides Learning,有监督和无监督两种学习方式的混用,即一种具有监督形式的无监督学习方法,模型在学习过程中进行自我监督,而不是通过前置知识来诱发。
同样,自监督学习没有预设的标签,而是使用数据集本身的信息构造标签,即通过构造辅助任务(pretask)完成学习。该方法衍生出来的 transformer 被命名为 Bidirectional Encoder Representations from Transformers(BERT),被广泛应用于现代大模型的预训练中。
再谈谈 GPT
毕竟 DeepSeek 从各方面对标的就是目前大模型中的翘楚 —— GPT,我们聊完深度学习基础后,首先深入浅出地了解一下 GPT。
GPT 的全称是 Generative Pre-trained Transformer。
GPT-1
12 层(个)decoder-only transformer,单头维度 768,参数量 0.117B。
- 采用无监督预训练 + 有监督微调的方式,因此不是完全的 zero-shot;
- 其无监督预训练基于语言模型进行,模型参数使用 SGD(Stochastic Gradient Descent, 随机坡度下降)进行优化。
GPT 的参数中有一个叫 token,由一个特定维度大小的向量组成,类似于 Lucene 的分词器:一段话里面,如果能够分成 5 个单位(单词、标点符号、英文句子的字母等),意味着这句话消耗了 5 个 token;不同的模型支持的上下文长度不一样,有的 2048,有的 200k。
另外,GPT 采用多任务学习(Multi-task Learning)的方向,多个不同目标和不同结构的任务并行处理,有效提升了泛化性。
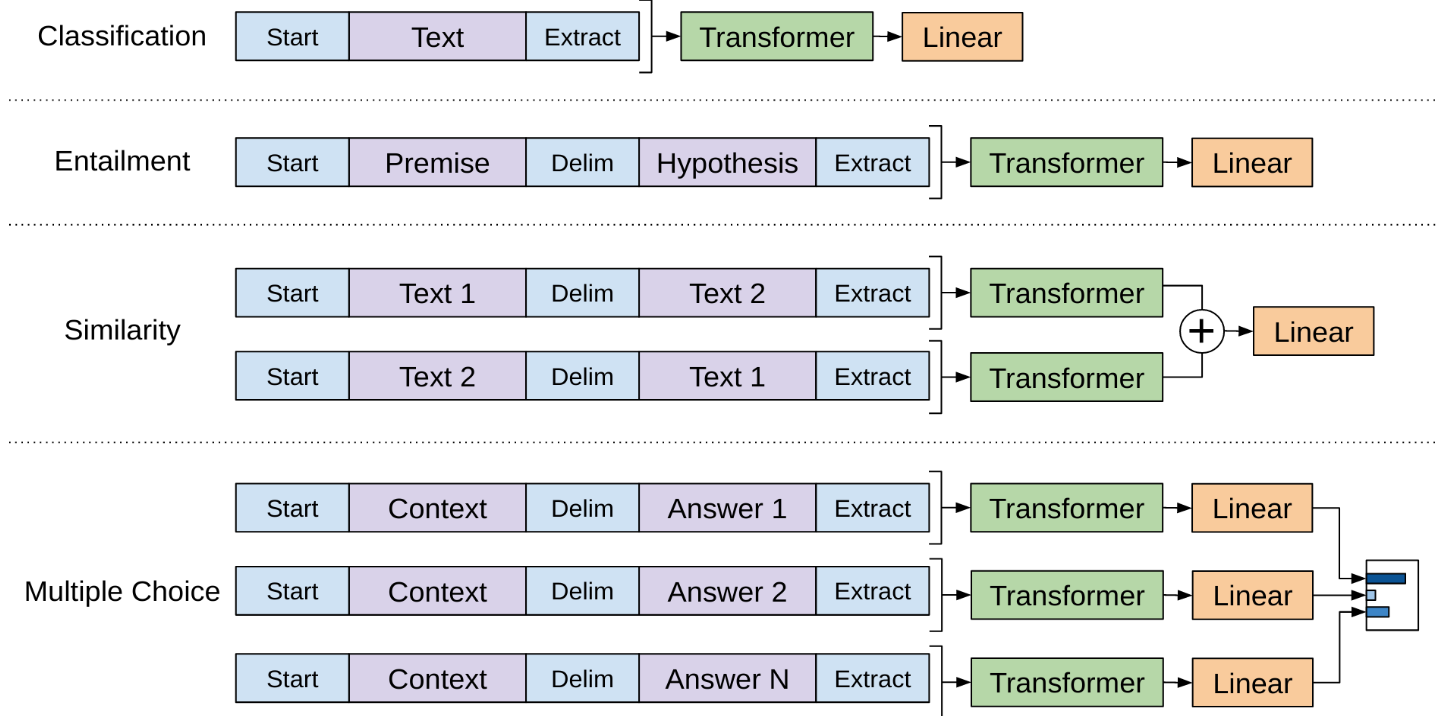
GPT-2
48 层 decoder-only transformer,单头维度 1600,参数量 1.5B。
GPT-2 其实在模型和架构上没有可圈可点之处,主要贡献在于:随着模型参数和训练数据的海量增长,只用 zero-shot 也可以达到相当高的模型准确性,这个特点后来被总结为 scaling law。
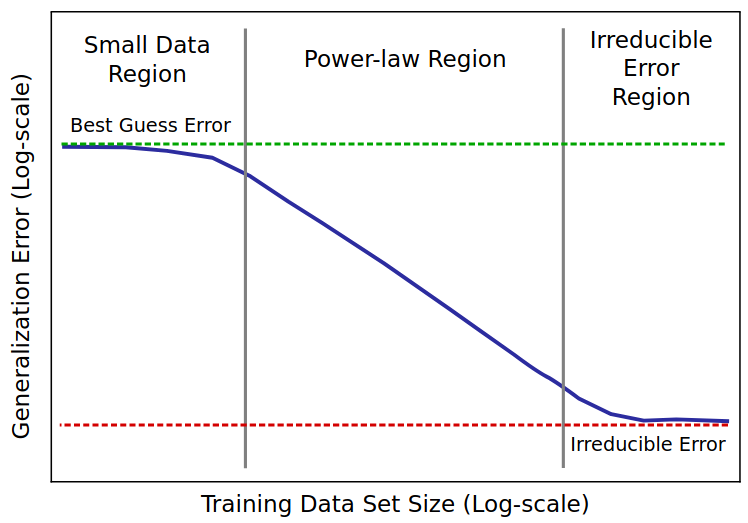
GPT-3
96 层 decoder-only transformer,单头维度 12888,参数量 175B,真正火起来的一代 GPT,相比较于前两代更为强大。
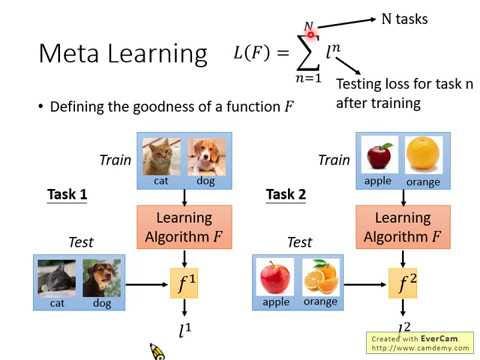
重要的技术点在于 meta learning 和 in-context learning
meta learning:元学习,针对传统机器学习中由人设计的学习算法,改成由机器设计学习算法,即根据学习资料确定学习函数。
meta learning 的一种实现叫 MAML(Model-Agnostic Meta-Learning),将输入 transformer 的 batch 再分为 support set 和 query set,类似于模型学习时的训练集和测试集。
meta learning 和预训练的差异在于:预训练更关注于当前任务的准确性,而元学习更加关注潜力,关注未来,二者梯度的更新方向不同。
in-context learning:上下文学习,指在不进行参数更新的情况下,只在输入中加入几个示例就能让模型进行学习。
in-context learning 属于 GPT-2 的扩展。
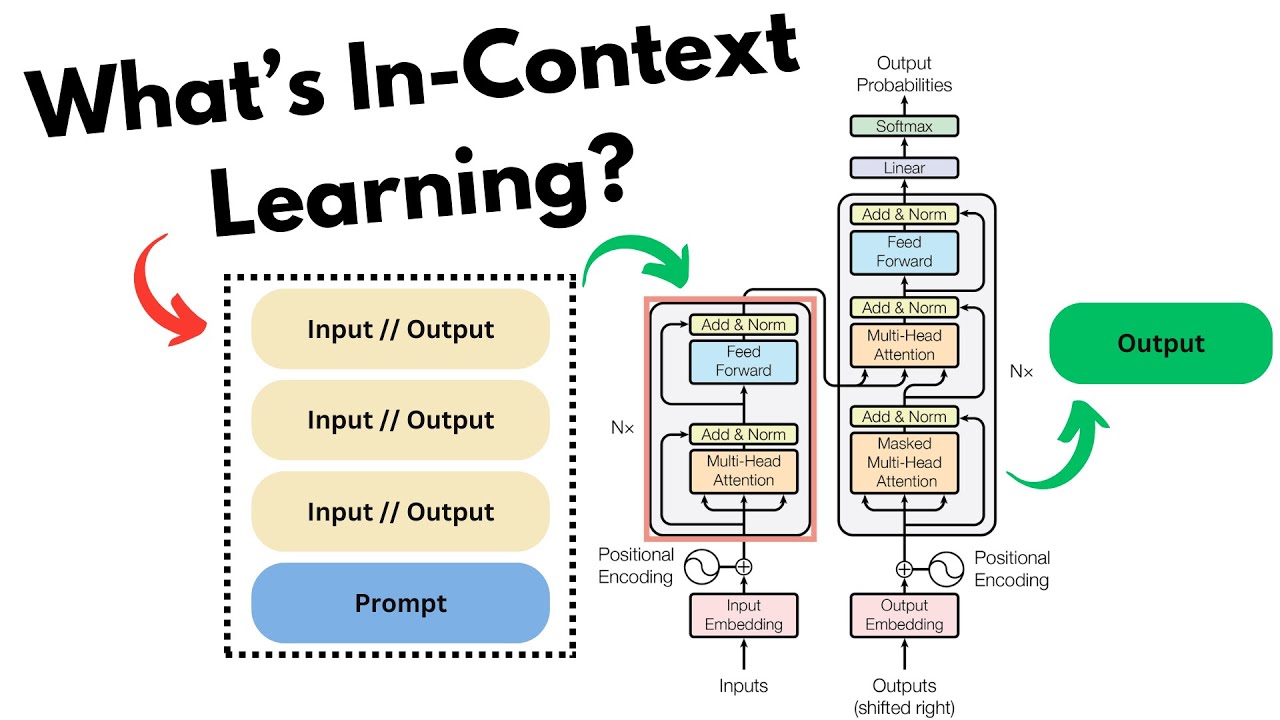
GPT-3 中介绍的 in-context learning 是作为 meta learning 的内循环出现的,而基于 SGD 的预训练则是外循环。
ChatGPT
提示学习与指示学习
两者的目的都是去挖掘语言模型本身具备的知识,不同的是:
- Prompt Learning,提示学习,激发语言模型的补全能力(完形填空、上半句生下半句等);in-context learning 被认为是提示学习的一种;
- Instruction Learning,指示学习,激发语言模型的理解能力,通过给出更明显的指令让模型做出正确的行动
Instruction 比 prompt 更具泛化能力,在经过多任务微调后还能做 zero shot。
强化学习
训练得到的模型可以看做是训练集的一个拟合。因为此时得到的模型并不非常可控,那么训练数据的分布就是影响生成内容质量的最重要因素。
有的时候我们希望模型不仅仅是受到训练数据的影响,而是人为可控的,从而保证生成数据的有用性、真实性、无公害性,因此我们需要需要人为的介入,目前 GPT 介入的方式就是奖励(Reward)机制,带奖励机制的学习方式就是强化学习(Reinforcement Learning, RL)。
奖励机制可以被看作是传统模型训练机制的损失函数,其计算要比损失函数更灵活和多样;带来的代价是奖励计算不可导,因此不能拿来反向传播;同样人类反馈也是不可导的,故人工反馈也可作为强化学习的奖励。
强化学习通过对奖励的大量采样来拟合损失函数,以最大化长期累积奖励,从而实现模型的训练。
小结
综上,基于 GPT-3 的 ChatGPT 通过指示学习构建训练样本,以此来训练一个反映预测内容效果的奖励模型(Reward Model),最后通过模型的打分来指导强化学习模型的训练。步骤如下:
- 根据采集的数据集对 GPT-3 进行有监督微调(Supervised Fine-Tune, SFT);
- 收集人工标注的对比数据,训练奖励模型(Reward Model, RM);
- 使用 RM 作为强化学习的优化目标,利用 PPO(Proximal Policy Optimization,最近策略优化,可在多个训练步骤实现小批量的更新,解决了 Policy Gradient 算法中步长难以确定的问题)微调 SFT 模型
算力
综上我们很容易得知,堆 transformer 的做法势必会带来算力要求的飞速增长。
DeepSeek
DeepSeek 泛指且不限于以下的模型:
- DeepSeek-V3:对话模型,最新的 DeepSeek 底座
- DeepSeek-R1:推理模型,准确率相较于 DeepSeek V3更高,但思考过程过长
- DeepSeek-R1-zero:推理模型,DeepSeek-R1 的先验版本,验证了 RL 本身对于激励 base 模型产生推理的能力
- DeepSeek-R1-Distill-XXX-XXB:知识蒸馏版的推理模型。以 DeepSeek-R1-Distill-Qwen-7B 为例,使用 DeepSeek R1 中间阶段的训练数据,对 Qwen 2.5(参数量为 7B)进行 SFT 指令微调的模型。
DeepSeek 总的特点在于,它完全抛开了预设的思维链模板(Chain of Thought)和监督式微调(SFT),仅依靠简单的奖惩信号(准确性奖励 <think> 和格式奖励 <answer>)来优化模型行为。
就本人肤浅的观察来看,DeepSeek 能够以 10% 不到的资源达到众多顶尖大模型的水平,采用的关键技术有两个:
MLA
Multi-head Latent Attention,多头潜在注意力机制,通过动态合并(压缩 + 复用)相邻层的特征(K V)来减少计算量。
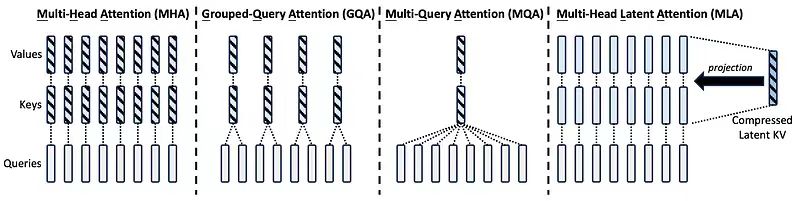
同样的降本思路还在于 FP8,牺牲了一些精度来换取效率。
属实是:
既然 GPU 少,那就卷工程,DeepSeek 这回确实是用东亚魔法打破西方垄断。
MoE
Mixture of Experts,混合专家模型,通过训练多个专家模型,每个专家针对特定的数据分布或任务进行优化。通过门控机制动态选择最合适的专家模块进行处理,从而提高模型的推理能力和效率。
与多任务学习(一个模型内多个学习任务)不同,MoE 是利用多个专家模型处理输入数据的不同方面或模式,通过门控网络决定如何将输入分配给各个专家,以及如何加权各位专家的输出。
Reference
- Neural Machine Translation by Jointly Learning to Align and Translate
- Attention Is All You Need
- 从 0 到 1 理解 GPT3
- 动画图解 Attention 机制,让你一看就明白
- What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- DeepSeek-V3 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 🧐 DeepSeek-R1 原理解析及项目实践(含小白向概念解读)
- 省钱也是技术活:解密 DeepSeek 的极致压榨术