Binary search tree,也叫二叉查找树、有序二叉树。
搜索树
先来说说搜索树。
提出搜索树的背景,是使用散列描述字典时遇到了瓶颈。
先是按关键字的升序输出字典元素:
- 使用除数为 D 的链表,需要 时间内取出元素, 时间内排序, 时间内输出:因此一共需要 单位的时间;
- 对散列使用线性开型寻址:需要 ,其中取出元素需要 , 是桶的个数。
随后,是按升序找到第 k 个元素 / 删除第 k 个元素。
- 以上两个场景,如果使用链表来描述,需要在 时间内完成
- 如果使用线性开型寻址,则时间复杂度是
- 必须采用线性时间确定 n 元素集合中第 k 个元素
因此搜索树,尤其是二叉搜索树适合描述字典,即:使用搜索树描述 n 个元素的字典:
- 搜索、插入或删除所需的平均时间和最坏时间均为
- 按关键字升序输出元素:
- 按元素排名查找和删除操作耗时
- 所有字典元素能在线性时间内按升序输出
- 无论是平衡还是非平衡的搜索树,顺序访问某个元素平均所需时间为
搜索树是基础性数据结构(ADT),用于构建更为抽象的数据结构,如集合、multiset、关联数组等。
相比于其他数据结构,二叉搜索树的优势在于查找、插入、删除的时间复杂度较低,最坏时间复杂度为 。
常见的搜索树有:
- 自平衡二叉树,包括 AVL 树、红-黑树
- B 树:对读写操作进行优化的自平衡 N 叉搜索树,非叶子节点里拥有多于两个子节点
特征
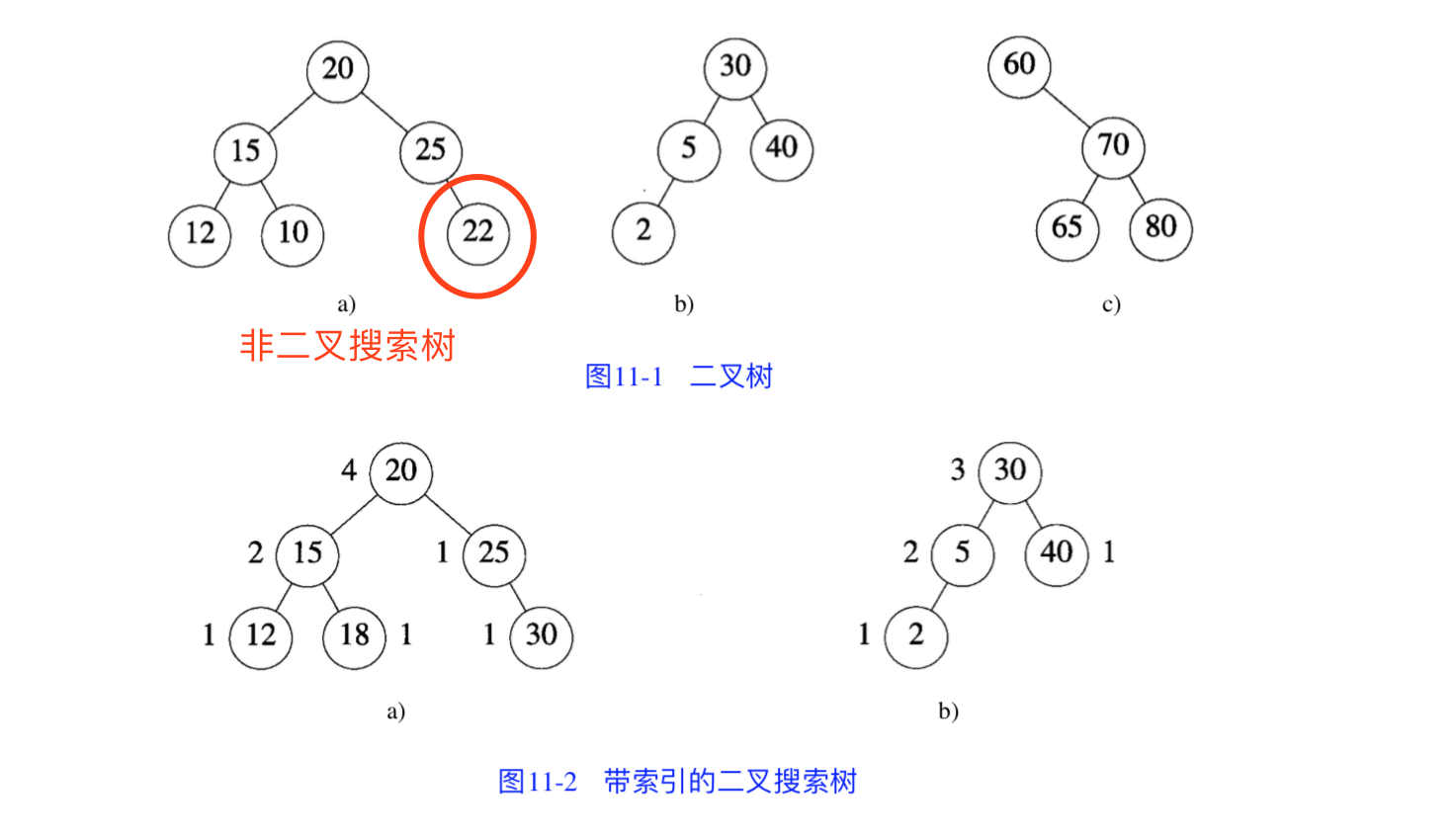
二叉搜索树满足以下特征:
- 若任意节点左子树非空,则左子树上所有节点的值均 <(小于)其根节点的值
- 若任意节点右子树非空,则右子树上所有节点的值均 >(大于)其根节点的值
- 任意节点的左、右子树也分别为二叉查找树
- 每个节点有一个关键值(key),没有键值相等的节点(no duplicate nodes)
注:如将“小于”换成“小于等于”,“大于”换成“大于等于”,则会得到一棵有重复值的二叉搜索树
延伸:带索引的(indexed)二叉搜索树
- 在每个节点中添加一个 LeftSize 域
- 该域值为该节点左子树的元素个数加一
- 该值同时给出了一个元素在子树中的排名
- 调用中序输出 InOrderOutput 将二叉搜索树按照升序输出:
- 搜索:按照索引查找
- 插入:需要更新插入沿途所有节点的 LeftSize 值:
操作与实现
先定义二叉搜索树的节点类 BinaryTreeNode
1
2
3
4
5
6
7
8
9
10
| class BinaryTreeNode {
private String data = null;
private BinaryTreeNode leftChild = null;
private BinaryTreeNode rightChild = null;
...
}
|
跟普通二叉树的节点没区别。
二叉搜索树除了拥有普通二叉树的方法(前中后序遍历、层级遍历、比较、复制等),其基本操作方法会有所区分,比如最基本的几个:
指导思想:比根节点大的,往右子树找;比根节点小的,往左子树找;否则,当前节点就是你要的节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| BinaryTreeNode<T> search(T value) {
if (root == null) {
System.err.println("Tree null.");
return null;
}
if (value == null) {
System.err.println("No operation for null value.");
return null;
}
BinaryTreeNode<T> curr = root;
while (value != curr.getValue()) {
curr = value.compareTo(curr.getValue()) > 0 ?
curr.getRightChild() : curr.getLeftChild();
if (curr == null) {
return null;
}
}
return curr;
}
|
时间复杂度为 ,其中 h 为树的高度。
指导思想:比根节点大的,往右子树插入;比根节点小的,往左子树插入;不接受已存在的节点值的添加。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public void insertNode(T value) {
if (value == null) {
System.err.println("Please do not insert a null value.");
return;
}
if (root == null) {
root = new BinaryTreeNode<>(value);
return;
}
BinaryTreeNode<T> node = new BinaryTreeNode<>(value);
BinaryTreeNode<T> curr = root;
while (true) {
BinaryTreeNode<T> parent = curr;
if (value.compareTo(curr.getValue()) > 0) {
curr = curr.getRightChild();
if (curr == null) {
parent.setRightChild(node);
return;
}
} else if (value.compareTo(curr.getValue()) < 0) {
curr = curr.getLeftChild();
if (curr == null) {
parent.setLeftChild(node);
return;
}
} else {
System.err.println("Node " + value + " already there.");
return;
}
}
}
|
二叉搜索树删除节点 p,分三种情况:
- p 是树叶:直接删除
- p 只有一棵非空子树
- p 没有父节点(即 p 为根节点):将 p 丢弃,p 的唯一子树的根节点成为新的搜索树根节点
- p 存在父节点 pp:修改 pp 指针,令其指向 p 的唯一子树
- p 有两棵非空子树
- 将 p 替换为其左子树的最大值(前驱节点),或者右子树的最小值(后驱节点)
- 寻找左子树最大元素:沿着子树各节点的右孩子指针移动,直到右孩子指针为
null
- 寻找右子树最小元素:沿着子树各节点的左孩子指针移动,直到左孩子指针为
null
注意:如果节点 p 的左子树为空,则 p 的前驱节点为 p 的第一个有右孩子且左子树没有 p 节点的祖先。
举个例子:
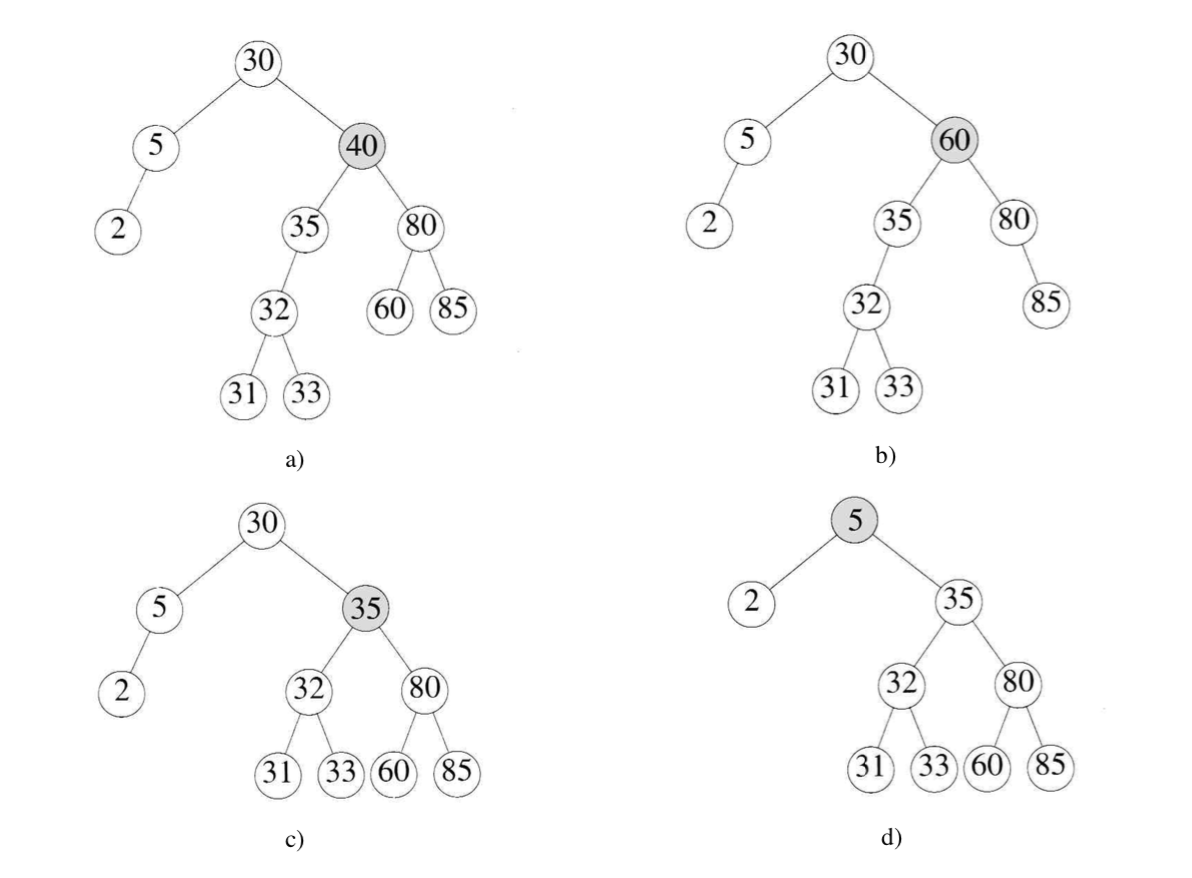
如上图,当我们要删除 a) 中值为 40 的元素的时候:
- 可以选择其右子树的最小值(60)为新的父节点,如
b) 所示
- 也可选择其左子树的最大值(35)为新的父节点,如
c) 所示
- 节点选择完毕并删除后,搜索树需要重新构建。
再比如:删除 c) 中值为 30 的元素,如选择其左子树的最大值(5)为新的父节点,便如 d) 所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| public boolean deleteNode(T value) {
if (root == null) {
System.err.println("Tree null. Deletion failed.");
return false;
}
if (value == null) {
System.out.println("No operation for null value.");
return false;
}
BinaryTreeNode<T> curr = root;
BinaryTreeNode<T> parent = root;
boolean isInLeft = true;
while (value != curr.getValue()) {
isInLeft = value.compareTo(curr.getValue()) < 0;
parent = curr;
curr = isInLeft ? curr.getLeftChild() : curr.getRightChild();
if (curr == null) {
System.err.println("Element not found.");
return false;
}
}
if (curr.getLeftChild() == null && curr.getRightChild() == null) {
System.out.println("Deleting leaf " + value + ".");
if (isInLeft) {
parent.setLeftChild(null);
} else {
parent.setRightChild(null);
}
return true;
}
if (curr.getLeftChild() == null || curr.getRightChild() == null) {
boolean isLeftExist = curr.getLeftChild() != null;
System.out.println("Deleting node " + value + " with " +
(isLeftExist ? "left" : "right") + " child.");
if (isInLeft) {
parent.setLeftChild(isLeftExist ? curr.getLeftChild() : curr.getRightChild());
} else {
parent.setRightChild(isLeftExist ? curr.getLeftChild() : curr.getRightChild());
}
return true;
}
System.out.println("Deleting node " + value + " with children.");
BinaryTreeNode<T> predecessor = getPredecessorTree(curr);
if (root == curr) {
root = predecessor;
} else if (isInLeft) {
parent.setLeftChild(predecessor);
} else {
parent.setRightChild(predecessor);
}
predecessor.setRightChild(curr.getRightChild());
return true;
}
BinaryTreeNode<T> getPredecessorTree(BinaryTreeNode<T> node) {
if (node == null) {
return null;
}
BinaryTreeNode<T> predParent = node;
BinaryTreeNode<T> predecessor = node;
BinaryTreeNode<T> curr = node.getLeftChild();
while (curr != null) {
predParent = predecessor;
predecessor = curr;
curr = curr.getRightChild();
}
if (predecessor != node.getLeftChild()) {
predParent.setRightChild(predecessor.getLeftChild());
predecessor.setLeftChild(node.getLeftChild());
}
return predecessor;
}
|
时间复杂度为 ,其中 h 为树的高度。
- n 个元素的二叉搜索树高度可以为 n,但其平均时间为 。